A survey of robots.txt - part two
Mar 22, 2018 · 6 minute readIn part one of this article, I collected robots.txt from the top 1 million sites on the web. In this article I’m going to do some analysis, and see if there’s anything interesting to find from all the files I’ve collected.
First we’ll start with some setup.
1%matplotlib inline
2
3import pandas as pd
4import numpy as np
5import glob
6import os
7import matplotlib
Next I’m going to load the content of each file into my pandas dataframe, calculate the file size, and store that for later.
1l = [filename.split('/')[1] for filename in glob.glob('robots-txt/\*')]
2df = pd.DataFrame(l, columns=['domain'])
3df['content'] = df.apply(lambda x: open('robots-txt/' + x['domain']).read(), axis=1)
4df['size'] = df.apply(lambda x: os.path.getsize('robots-txt/' + x['domain']), axis=1)
5df.sample(5)
| domain | content | size | |
|---|---|---|---|
| 612419 | veapple.com | User-agent: *\nAllow: /\n\nSitemap: http://www... | 260 |
| 622296 | buscadortransportes.com | User-agent: *\nDisallow: /out/ | 29 |
| 147795 | dailynews360.com | User-agent: *\nAllow: /\n\nDisallow: /search/\... | 248 |
| 72823 | newfoundlandpower.com | User-agent: *\nDisallow: /Search.aspx\nDisallo... | 528 |
| 601408 | xfwed.com | #\n# robots.txt for www.xfwed.com\n# Version 3... | 201 |
File sizes
Now that we’ve done the setup, let’s see what the spread of file sizes in robots.txt is.
1fig = df.plot.hist(title='robots.txt file size', bins=20)
2fig.set_yscale('log')
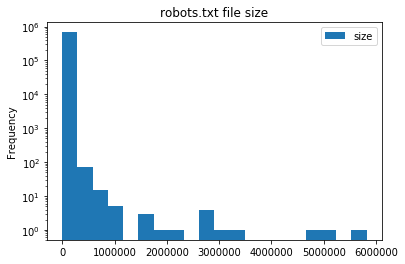
It looks like the majority of robots.txt are under 250KB in size. This is really no surprise as robots.txt supports regex, so complex rulesets can be built easily.
Let’s take a look at the files larger than 1MB. I can think of three possibilities: they’re automatically maintained; they’re some other file masquerading as robots.txt; or the site is doing something seriously wrong.
1large = df[df['size'] > 10 ** 6].sort_values(by='size', ascending=False)
1import re
2
3def count_directives(value, domain):
4content = domain['content']
5return len(re.findall(value, content, re.IGNORECASE))
6
7large['disallow'] = large.apply(lambda x: count_directives('Disallow', x), axis=1)
8large['user-agent'] = large.apply(lambda x: count_directives('User-agent', x), axis=1)
9large['comments'] = large.apply(lambda x: count_directives('#', x), axis=1)
10
11# The directives below are non-standard
12
13large['crawl-delay'] = large.apply(lambda x: count_directives('Crawl-delay', x), axis=1)
14large['allow'] = large.apply(lambda x: count_directives('Allow', x), axis=1)
15large['sitemap'] = large.apply(lambda x: count_directives('Sitemap', x), axis=1)
16large['host'] = large.apply(lambda x: count_directives('Host', x), axis=1)
17
18large
| domain | content | size | disallow | user-agent | comments | crawl-delay | allow | sitemap | host | |
|---|---|---|---|---|---|---|---|---|---|---|
| 632170 | haberborsa.com.tr | User-agent: *\nAllow: /\n\nDisallow: /?ref=\nD... | 5820350 | 71244 | 2 | 0 | 0 | 71245 | 5 | 10 |
| 23216 | miradavetiye.com | Sitemap: https://www.miradavetiye.com/sitemap_... | 5028384 | 47026 | 7 | 0 | 0 | 47026 | 2 | 0 |
| 282904 | americanrvcompany.com | Sitemap: http://www.americanrvcompany.com/site... | 4904266 | 56846 | 1 | 1 | 0 | 56852 | 2 | 0 |
| 446326 | exibart.com | User-Agent: *\nAllow: /\nDisallow: /notizia.as... | 3275088 | 61403 | 1 | 0 | 0 | 61404 | 0 | 0 |
| 579263 | sinospectroscopy.org.cn | http://www.sinospectroscopy.org.cn/readnews.ph... | 2979133 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 55309 | vibralia.com | # robots.txt automaticaly generated by PrestaS... | 2835552 | 39712 | 1 | 15 | 0 | 39736 | 0 | 0 |
| 124850 | oftalmolog30.ru | User-Agent: *\nHost: chuzmsch.ru\nSitemap: htt... | 2831975 | 87752 | 1 | 0 | 0 | 87752 | 2 | 2 |
| 557116 | la-viephoto.com | User-Agent:*\nDisallow:/aloha_blog/\nDisallow:... | 2768134 | 29782 | 2 | 0 | 0 | 29782 | 2 | 0 |
| 677400 | bigclozet.com | User-agent: *\nDisallow: /item/\n\nUser-agent:... | 2708717 | 51221 | 4 | 0 | 0 | 51221 | 0 | 0 |
| 621834 | tranzilla.ru | Host: tranzilla.ru\nSitemap: http://tranzilla.... | 2133091 | 27647 | 1 | 0 | 0 | 27648 | 2 | 1 |
| 428735 | autobaraholka.com | User-Agent: *\nDisallow: /registration/\nDisal... | 1756983 | 39330 | 1 | 0 | 0 | 39330 | 0 | 2 |
| 628591 | megasmokers.ru | User-agent: *\nDisallow: /*route=account/\nDis... | 1633963 | 92 | 2 | 0 | 0 | 92 | 2 | 1 |
| 647336 | valencia-cityguide.com | # If the Joomla site is installed within a fol... | 1559086 | 17719 | 1 | 12 | 0 | 17719 | 1 | 99 |
| 663372 | vetality.fr | # robots.txt automaticaly generated by PrestaS... | 1536758 | 27737 | 1 | 12 | 0 | 27737 | 0 | 0 |
| 105735 | golden-bee.ru | User-agent: Yandex\nDisallow: /*_openstat\nDis... | 1139308 | 24081 | 4 | 1 | 0 | 24081 | 0 | 1 |
| 454311 | dreamitalive.com | user-agent: google\ndisallow: /memberprofileda... | 1116416 | 34392 | 3 | 0 | 0 | 34401 | 0 | 9 |
| 245895 | gobankingrates.com | User-agent: *\nDisallow: /wp-admin/\nAllow: /w... | 1018109 | 7362 | 28 | 20 | 2 | 7363 | 0 | 0 |
It looks like all of these sites are misusing Disallow and Allow. In fact, looking at the raw files it appears as if they list all of the articles on the site under an individual Disallow command. I can only guess that when publishing an article, a corresponding line in robots.txt is added.
Now let’s take a look at the smallest robots.txt
1small = df[df['size'] > 0].sort_values(by='size', ascending=True)
2
3small.head(5)
| domain | content | size | |
|---|---|---|---|
| 336828 | iforce2d.net | \n | 1 |
| 55335 | togetherabroad.nl | \n | 1 |
| 471397 | behchat.ir | \n | 1 |
| 257727 | docteurtamalou.fr | 1 | |
| 669247 | lastminute-cottages.co.uk | \n | 1 |
There’s not really anything interesting here, so let’s take a look at some larger files
1small = df[df['size'] > 10].sort_values(by='size', ascending=True)
2
3small.head(5)
| domain | content | size | |
|---|---|---|---|
| 676951 | fortisbc.com | sitemap.xml | 11 |
| 369859 | aurora.com.cn | User-agent: | 11 |
| 329775 | klue.kr | Disallow: / | 11 |
| 390064 | chneic.sh.cn | Disallow: / | 11 |
| 355604 | hpi-mdf.com | Disallow: / | 11 |
Disallow: / tells all webcrawlers not to crawl anything on this site, and should (hopefully) keep it out of any search engines, but not all webcrawlers follow robots.txt.
User agents
User agents can be listed in robots.txt to either Allow or Disallow certain paths. Let’s take a look at the most common webcrawlers.
1from collections import Counter
2
3def find_user_agents(content):
4 return re.findall('User-agent:? (.*)', content)
5
6user_agent_list = [find_user_agents(x) for x in df['content']]
7user_agent_count = Counter(x.strip() for xs in user_agent_list for x in set(xs))
8user_agent_count.most_common(n=10)
1[('*', 587729),
2('Mediapartners-Google', 36654),
3('Yandex', 29065),
4('Googlebot', 25932),
5('MJ12bot', 22250),
6('Googlebot-Image', 16680),
7('Baiduspider', 13646),
8('ia_archiver', 13592),
9('Nutch', 11204),
10('AhrefsBot', 11108)]
It’s no surprise that the top result is a wildcard (*). Google takes spots 2, 4, and 6 with their AdSense, search and image web crawlers respectively. It does seem a little strange to see the AdSense bot listed above the usual search web crawler. Some of the other large search engines’ bots are also found in the top 10: Yandex, Baidu, and Yahoo (Slurp). MJ12bot is a crawler I had not heard of before, but according to their site it belongs to a UK based SEO company—and according to some of the results about it, it doesn’t behave very well. ia_archiver belongs to The Internet Archive, and (I assume) crawls pages for the Wayback Machine. Finally there is Apache Nutch, an open source webcrawler that can be run by anyone.
Security by obscurity
There are certain paths that you might not want a webcrawler to know about. For example, a .git directory, htpasswd files, or parts of a site that are still in testing, and aren’t meant to be found by anyone on Google. Let’s see if there’s anything interesting.
1sec_obs = ['\.git', 'alpha', 'beta', 'secret', 'htpasswd', 'install\.php', 'setup\.php']
2sec_obs_regex = re.compile('|'.join(sec_obs))
3
4def find_security_by_obscurity(content):
5return sec_obs_regex.findall(content)
6
7sec_obs_list = [find_security_by_obscurity(x) for x in df['content']]
8sec_obs_count = Counter(x.strip() for xs in sec_obs_list for x in set(xs))
9sec_obs_count.most_common(10)
1[('install.php', 28925),
2('beta', 2834),
3('secret', 753),
4('alpha', 597),
5('.git', 436),
6('setup.php', 73),
7('htpasswd', 45)]
Just because a file or directory is mentioned in robots.txt, it doesn’t mean that it can actually be accessed. However, if even 1% of Wordpress installs leave their install.php open to the world, that’s still a lot of vulnerable sites. Any attacker could get the keys to the kingdom very easily. The same goes for a .git directory. Even if it is read-only, people accidentally commit secrets to their git repository all the time.
Conclusion
robots.txt is a fairly innocuous part of the web. It’s been interesting to see how popular websites (ab)use it, and which web crawlers are naughty or nice. Most of all this has been a great exercise for myself in collecting data and analysing it using pandas and Jupyter.
The full data set is released under the Open Database License (ODbL) v1.0 and can be found on GitHub